


Some "complete bullshit" about AI and energy
Musings on the impact of AI on energy demand... Plus: our extraordinarily efficient brains

First, a non-sequitur. (Or is it?)
AI versus photosynthesis
Photosynthesis is the OG mechanism for capturing solar energy. It’s a wonder of nature. And yet, by human technology standards, it’s almost laughably bad at its job.
Plants are only able to convert about 1-2% of solar radiation into chemical energy embodied in biomass (i.e. convert sunlight into more plant). Solar photovoltaic cells are more than ten times better than that at converting solar energy into electricity (which is a much more useful form of energy), with efficiencies in the range of 16-22%.
This is a major win for human technology, and it’s one of the reasons I’m extremely skeptical of biomass-based energy production strategies. If you have a big open field, and you want to extract useful energy from the incoming solar radiation, photovoltaics win hands down. If you really need energy in chemical form, rather than electrical form, photovoltaics still win; just run that solar power through an electrolyzer in order to produce hydrogen.

What on earth does this have to do with AI?
Probably…nothing. I’m only bringing it up because I find it very strange, given how bad nature is at converting sunlight to useful energy, just how insanely good nature is at converting energy into intelligence.
It took AI researchers about 433 MWh of energy to train a large language model (or LLM) with 176 billion parameters, called BLOOM. With that energy - enough to power about 40 typical US homes for a year - BLOOM learned 46 natural human languages and 13 programming languages. OpenAI’s GPT-3 model reportedly required 1.3 GWh to train, which is a little over three times more than BLOOM, and of course we’re all very impressed with ChatGPT’s language skills, too.
Meanwhile, my best estimate is that it takes about 4 MWh of energy to train a fully-formed, adult human brain to the age of 21, at which point we Americans recognize that brain as sufficiently intelligent to dumb itself down with alcohol. If you think of the rest of the body as basically just ancillary equipment to support the intelligence in the brain, then it takes about 20 MWh of energy input to nurture adult human intelligence.

Now, of course most human brains don’t learn as many languages as BLOOM or GPT, although it’s not entirely beyond our scope! But of course, we also learn all kinds of other useful things that LLMs don’t, like how to pick up a fork with a hand! (This sort of thing is shockingly hard to teach a robot hand to do.) Frankly, when it comes to learning nearly anything, the energy efficiency of the human brain is extraordinary. For example, it would take about ten minutes and a negligible amount of energy to teach a child how to fold an orgiami frog, while GPT could only respond “N/A” to that kind of prompt.

I think it’s fair to claim, at a minimum, that the human brain is currently at least a few orders of magnitude more energy efficient as a learning machine than the transformer-based neural networks currently driving most of the progress in AI.
More neural network, more energy?
About that current AI paradigm…
In pursuit of better & better AI, developers have been building bigger & bigger models. Hence, the plausibility of the rumor that GPT-4 has 500 times as many parameters as GPT-3. This rumor has lived on despite the CEO of OpenAI, Sam Altman, calling it “complete bullshit”.
Still, there’s no mistaking that models are getting bigger. And so far, there has been a fairly linear relationship between the number of parameters in a model and the amount of compute (“flops”) required to train that model. So, bigger models do demand more compute.

Fortunately, however, model training has become much more efficient over time, with the number of flops that a GPU can perform per watt of electrical power input increasing non-linearly. This is the result of a number of factors - including both hardware and algorithmic efficiency - which I haven’t seen disaggregated. In any case, GPU ‘compute efficiency’ for training AI models has increased by about 10X over the past ten years, as commercial interest in AI really began to take off.

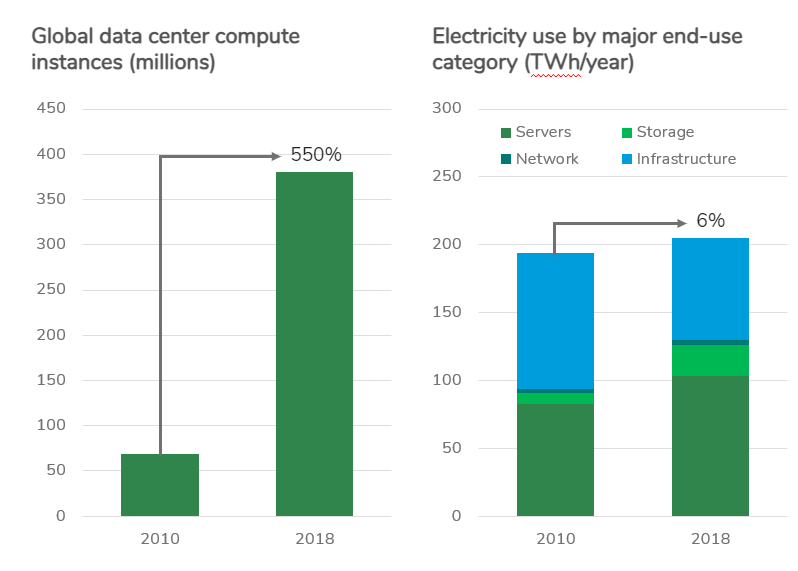
Thank goodness we’ve also seen a similar trend play out in data centers, writ large. From 2010 to 2018, global data center computing grew by more than 5X while total data center energy consumption grew by a mere 6%. This is an astonishingly fast ride down the efficiency learning curve!
Let the bullshitting commence
There are a bunch of ways of estimating how many parameters an AI model would need to truly match the cognitive potential of a human brain. Most approaches begin with the fact that the human brain has about 100 trillion synapses, which is coincidentally the number of parameters rumored to make up GPT-4 which Altman referred to as “complete bullshit”.
I’ll warn you that from here on out, all of my speculation might also be complete bullshit. This is more or less where scientific consensus on both human & artificial intelligence ends. There are all kinds of unknowns (both known & unknown) when it comes to translating neural synapses to machine learning model parameters. It’s also far from established that the current AI paradigm, which is based on building ever more complex layers of interconnected statistical models, is on the right path to achieve human-esque “general” intelligence. Some very smart humans have argued convincingly that it is not at all the right paradigm.
Still, let’s run with this bullshit. A relatively recent paper estimated that a real human neuron can do the work of about 1,000 artificial “neurons” in an AI neural network.1 This comparison suggests that a theoretical human-level AI would need about 100 quadrillion parameters (100 trillion synapses, multiplied by 1,000) in order to achieve human-brain-level capacity. That’s 500,000 times as many parameters as GPT-3.
If the energy efficiency of compute were to basically flatline moving forward, then training a single human-level AI would consume about 640 TWh, which is 16% of current annual US electricity demand. The energy cost alone would be about $25 billion, given even a relatively low industrial-scale electricity price of $.04/kWh.

Of course, compute efficiency is probably not going to flatline. Let’s assume we achieve another 10X efficiency gain in the next ten years.2 That would lead us to a very reasonable energy price tag of $2.5 billion (equivalent to 1.6% of US electricity generation) for human-brain-level AI.
Human beings, not human trainings
Most of the energy consumed by our brains is used to do stuff, not to learn stuff. The same is true for AI models.
I’ve established that training an AI is pretty energy-intensive - certainly much more energy intensive than training a human brain. If we continue along the path of building bigger & bigger models in a quest to achieve human-level capacity (or better), then it’s quite possible that AI training runs will bump up against practical energy supply constraints (at least, with regard to cost).
Unlike human brains, however, trained AI-models can be copy-pasted. For a negligible cost in energy, a single fully trained model can be deployed on a theoretically infinite number of servers. In other words, one training run can spawn an unlimited number of identical AI “instances”, which can simultaneously perform an unlimited number of cognitive tasks. Et tu, humans?
On the other hand, unlike copy-pasting a model, performing cognitive tasks does consume energy.
The cognitive task that’s currently in vogue for AI is responding to text queries. For reference, Google probably receives a few trillion queries per year.3 One credible estimate of ChatGPT’s energy consumption suggests that if ChatGPT were to respond to all of those queries, it would consume a few TWh of energy annually, which is a couple thousand times more energy than GPT-3 took to train.4 (It’s also about an order of magnitude more energy than Google search probably consumes today.5 )
Hence, utilizing any kind of AI model at global scale would probably consume a hell of a lot more energy than training that model in the first place. I haven’t found a great source to confirm whether there’s a strong linear relationship between a model’s parameter count and the compute required for utilization (like the relationship illustrated above between parameter count and compute required for training). But if there is a similar relationship, then actually making use of a human-brain-level model could quickly absorb much of our civilization’s energy!
Good enough models use a lot less energy
There are all kinds of cognitive tasks that don’t require human-level AI, or even GPT-level AI. Plus, for most tasks, there’s not even a relevant training dataset big enough to build a model with billions of parameters worth their watt-hours.
For example, in the energy sector, which I spend most of my time thinking about, there are all kinds of valuable ways of putting AI models to work. In fact, the industry began doing so several years before the so-called “large-scale” era in AI really began in earnest in 2017-2018.
Here are two examples I know well, from the EIP portfolio, that are employing much smaller models with excellent results:
eSmart Systems builds AI models to rapidly ingest and analyze images of energy infrastructure - for example, photos of electric transmission towers, collected by drones - and then automatically detect particular pieces of equipment on those towers, and possible defects in that equipment. This is a much more efficient way for utility companies to scan through hundreds of thousands, perhaps even millions of images of their assets. Also, imagine how error-prone human brains must be at such a tedious task!
Urbint builds AI models to ingest geospatial data, from a wide variety of sources, to identify risks to critical utility infrastructure. For example, it turns out that there are all kinds of variables one can gather, many from public sources, which can predict where rust will accumulate on natural gas pipes. (Rusty gas service lines are a major risk factor for gas leaks.) Urbint has also learned that AI can turn up surprisingly predictive relationships between all kinds of variables and worker safety incidents.
Needless to say, neither of these companies is guzzling up the world’s energy supply to train or run their models. That’s because they’ve right-sized their models for the tasks at hand, which don’t require LLM-scale AI.
Frankly, in all my years observing (and investing in) startup companies injecting AI into new products for energy industry operations, I’ve yet to see a company whose growth was ‘AI-constrained’. I can’t think of a single example of a product whose adoption was limited because the AI inside wasn’t good enough. Instead, where companies have stumbled, it’s been because of much more prosaic factors: lack of data availability; idiosyncrasies in human workflows which make automation a non-starter; and the difficulty of improving all that much on the status quo…which has already been honed through decades of human intelligence.
So, I’ll admit to being a skeptic that bigger, better AI will make much of a difference for energy or other large industrial operations.
Where I think bigger, better models will be most valuable is in more fundamental scientific pursuits - e.g. materials discovery - which are clearly the best parallels to generative AI for text or graphics. For example, I’m hopeful that applying next-level AI to this sort of task will accelerate materials selection for next generation batteries, PV cells, and all kinds of other clean energy hardware.
Re-education is cheap
There’s another development afoot which suggests that society won’t need big model training runs for every single application-specific AI.
After Meta’s LLM was leaked online, the open-source community began tinkering with a technique called “Low-Rank Adaptation”, or LORA, which enables fine-tuning existing models with new datasets, for specific applications. LORA can update massive models to be much better at particular tasks for about $100 and the power consumption of a laptop.
An anonymous google engineer leaked an internal memo about this approach, entitled “We have no moat”:
“LoRA updates are very cheap to produce (~$100) for the most popular model sizes. This means that almost anyone with an idea can generate one and distribute it. Training times under a day are the norm. At that pace, it doesn’t take long before the cumulative effect of all of these fine-tunings overcomes starting off at a size disadvantage. Indeed, in terms of engineer-hours, the pace of improvement from these models vastly outstrips what we can do with our largest variants, and the best are already largely indistinguishable from ChatGPT. Focusing on maintaining some of the largest models on the planet actually puts us at a disadvantage.”
In other words: from one big, well-trained, foundational model might spring thousands of model descendants targeting specific use cases.
A few conclusions
Human brains are a miracle of energy efficiency.
Without a paradigm shift in how we do AI, approaching anything resembling general, human-level intelligence would probably break the energy system.
We don’t really need superior AI to unlock a myriad of really valuable applications. For most applications, we can make do with sub-GPT-scale tools. For others, we can re-educate existing large-scale models super cheaply.
Thanks to “Towards Data Science” for pointing this one out, and summarizing it, as neuroscience is well above my pay grade.
I honestly have no idea how reasonable this assumption is. Compute efficiency opportunities are a big area of interest and research for us at EIP.
I haven’t found a definitive estimate of Google’s query volume, but have seen estimates in this range reported.
This is based on an assumption of .002-.003 kWh per query for ChatGPT, which is another estimate I’m relying on from Towards Data Science.
In 2011 the NYT reported that Google consumes about .0003 kWh per search, which was about 15% of the energy consumption per query for ChatGPT in 2023. Given that average data center energy consumption has improved by 5.5X since roughly that time, and Google is at the leading edge of data center efficiency, I’ll bet that the energy consumption differential between a Google query and a ChatGPT query is even more stark.