


Why does nobody know how much energy AI will consume?
Because of four big, interrelated variables


We are astoundingly in the dark about a phenomenon that everyone in the world is paying attention to.
Everybody (and their mother) is trying to understand data centers. Their proliferation is one of the hottest topics in business — especially in the electric power sector. It’s no coincidence that data centers, and all of the processors housed within, are rated in the units of electricity: kilowatts and megawatts. In essence, a data center is a big box in which electrons are converted into bits.
And these days, a lot of those bits are being used for AI.
Hence, AI news has become energy news, which is moving markets. For example, when the Chinese AI model DeepSeek first made waves on January 27 as an ostensibly more efficient approach to model development, the independent power producer Constellation Energy Group lost a fifth of its market capitalization overnight.
The importance of this trend is widely recognized, and the market is being closely followed by a horde of analysts. So, why do none of those analysts agree on how much power data centers will consume — even in just the next few years?
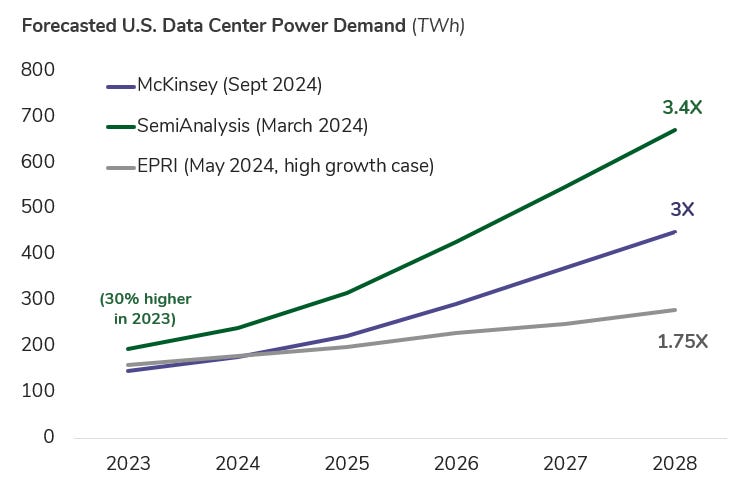
This is just a small sample of data center power demand forecasts published over the past year by respectable forecasting shops. (For what it’s worth, I personally view SemiAnalysis as the most credible source in this domain.)
So why are data center forecasts so uncertain?
The future of data center power consumption depends on four big, interrelated variables.

AI demand and profitability: How much demand will there will be for AI products? And will the business of developing AI become more financially sustainable?
Algorithmic evolution: How much more computationally efficient will AI algorithms become? And what balance will they strike between adding more computation during the “training” phase versus the “inference” phase?
Computing hardware efficiency: How much more efficiently can all of the stuff inside of a data center be designed to convert watts into bits?
Power supply constraints: Regardless of how all these prior questions are answered… How much power will realistically be available for data centers to consume?
Let’s consider these variables one by one.
AI demand & profitability
AI is getting very, very good.
How good? There are all sorts of benchmarks one can turn to for an answer to this question. One useful benchmark is the rate of “hallucinations” which large language models produce in response to queries. Because LLMs are basically giant statistical engines, their responses are sometimes statistically correct, but still made of whole cloth.
Courtesy of a company called Vectara, it’s easy to follow the industry’s progress on hallucinations. As of just one year ago, in June 2024, the lowest hallucination rate among leading-edge models was around 2.5%. (GPT-4 Turbo would just make something up in its response to about 1 out of every 40 queries.) Now there are multiple models which have achieved a hallucination rate below 1%.
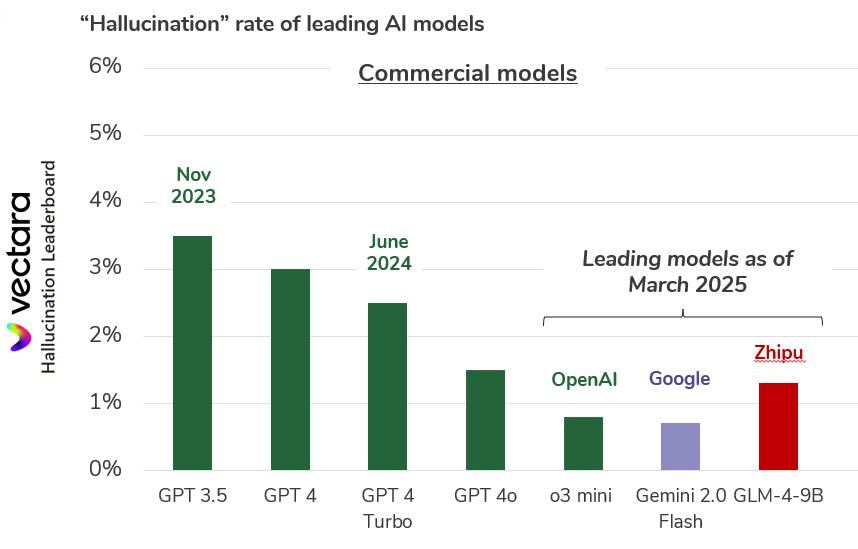
Personally, I’m finding the latest set of “deep research” tools from the likes of OpenAI and Google to be markedly better than their model forebears at digging up useful information from across the web, and presenting a concise summary. (Apparently, my personal threshold for B.S. is somewhere between 1% and 3%.)
As I wrote in my last post, “An Ode to Physical AI”:
Just how earth-shattering LLMs will be remains to be seen. But, there are a number of fields in which they’re already proving transformational— for example: translation, software development, customer service, and illustration. LLMs have also shown great promise in the realm of search & synthesis — scanning through vast quantities of digital documents in order to extract and integrate disparate bits of information.
This kind of tool can already replace a substantial amount of dull human labor. For example, my firm Energy Impact Partners just invested in a company called Atomic Canyon, which has honed an LLM to automate compliance documentation for nuclear power plants. There are currently 54 operational nuclear power plants in the United States, and “Neutron” could save thousands of hours of effort per year at every one of them.
On the other hand, GenAI is still very much in the “finding product-market fit” stage of development. Benedict Evans, a prominent tech industry analyst, has pointed out that AI adoption numbers reveal a nuanced story. Roughly a third of Americans now employ some kind of “generative AI chatbot” at least once a week. But only 10% have graduated to become “Daily Active Users” — which are the kind of users that industry analysts consider to be effectively hooked. Moreover, there was very little movement in these numbers throughout the second half of 2024…

Of course, AI will continue to improve. And entrepreneurs will continue experimenting with creative ways of embedding these models in regular workflows. Almost surely, these two trends will lead to greater adoption.
But just how much AI will continue to improve, and just how well AI models will take over from prior workflows, are still very big questions.
To some extent, the answer to both of these questions depends on the financial sustainability of investing in AI. Here, too, there is a substantial amount of uncertainty. Currently, “AI companies” are able to raise seemingly unlimited amounts of capital from investors who are entranced by AI’s theoretical potential. Developers of leading-edge “foundation models” have been plowing exponentially more capital into successive generations of their models, with the hope of unlocking the next level of performance. Yet, none of the leaders in this market have been able to pull ahead for long. This is why the technology investor Gavin Baker (of Atreides Management) struck a nerve back in 2023, when he referred to foundation models as “the fastest depreciating assets in history”.

This state of affairs certainly doesn’t seem all that financially sustainable. It may turn out that all this investment in GenAI is extremely valuable for society, but not all that profitable for investors! Yet the tantalizing, theoretical, “winner take all” promise of artifical general intelligence — which has prompted comparisons to the Space Race, and the invention of the Atomic Bomb — has kept investors hooked.
Will they stay hooked? Who knows! That’s yet another source of uncertainty.
Algorithmic Evolution
Forever ago, back in January 2020, a team of researchers at OpenAI published a paper called “Scaling Laws for Neural Language Models”, which observed a number of key relationships between the performance of large language models and the scale of three critical “factors of production”: the size of the model, the size of the dataset, and the amount of computing resources used during model “training”. The researchers found these relationships to be stable over a range of more than seven orders of magnitude for each factor. In sum:
“Language modeling performance improves smoothly as we increase the model size, dataset size, and amount of compute used for training. For optimal performance all three factors must be scaled up in tandem. Empirical performance has a power-law relationship with each individual factor when not bottlenecked by the other two.”
For the next four years, all three critical inputs were scaled in parallel, by about 3-4 orders of magnitude. This strategy worked so well that, in some circles, “scaling laws” came to be revered as natural laws, rather than empirical observations.
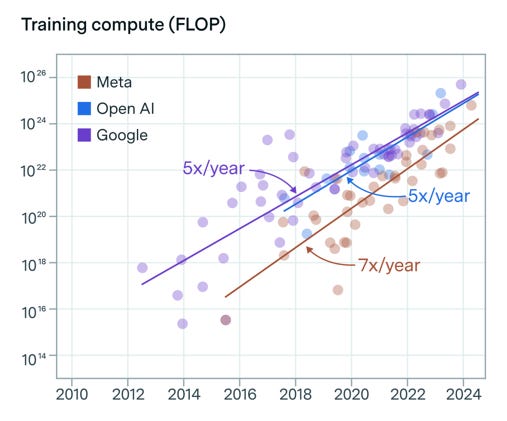
But around November of last year, public reports began to surface that these scaling laws were no longer holding up. In part, that’s because the internet does actually contain a finite amount of text, audio, and video data. (And once an AI algorithm has soaked up a billion tweets, how valuable is one more?) But even more crucially, the industry also appeared to be bumping up against another kind of scaling law — one which has stood the test of time across practically all sectors of the economy: diminishing marginal returns.

However, it didn’t take long for the industry to discover a new set of “scaling laws”. Rather than plowing more compute into the initial training phase of an AI model’s life cycle, developers have begun enlisting more computing resources during the “inference” phase, as the model responds to queries. This strategy is referred to as “chain of reasoning” or “test time compute” — which refers to the additional time that these models devote to “thinking”: decomposing tasks into steps, generating multiple alternative answers, and recursively honing in on the best response.
This class of models has been labeled “reasoning models”, and the results are very impressive — particularly in the case of questions which require logical deduction. Here’s a head-to-head comparison of OpenAI’s first reasoning model, “o1”, versus its closest cousin, “gpt4o”.

Why does this matter for data center power consumption? Two reasons.
First: Because more extreme growth forecasts tend to be predicated on scaling laws continuing to be the prime movers in the industry. (See, for example, Eric Schmidt’s recent assertion that AI could grow to consume “99% of total power generation”.)
Second: Because there’s a big difference in the kinds of data center needs implied by these divergent sets of “scaling laws”.
Scaling up for model training suggests:
Ideally, a single mammoth data center, typically running for 3-6 months straight, with minimal stops & starts.
Hundreds of megawatts, if not gigawatts of capacity in a single location.
Howewer, because latency is generally not an issue during the training phase of a model’s life-cycle, the precise location of these massive data centers is not particularly important. They can theoretically be punked down in the middle of nowhere, where there is plenty of space to build lots of low-cost wind or solar power.
Scaling up for inference suggests:
More computing demand will be spread across many individual instances, with lower capacity needs per instance (probably watts to megawatts).
Some applications will be extremely latency-sensitive, which means clustering as closely as possible around established data center hubs, which tend to be located near big population centers. Examples applications include customer service chatbots, AI “agents” tasked with working across multiple cloud applications, and “co-pilots” which are deeply embedded in continuous user workflows.
Some applications, however, probably have substantial flexibility regarding when and where they are executed. Examples include a wide range of "deep research” and other discrete “project-based” tasks.
Generally speaking, any model deployed at scale will consume vastly more energy during the inference phase of its lifecycle — when it’s being used by thousands, millions, or even billions of people — than during the training phase. ChatGPT, for example, reportedly consumed more than three times as much energy in its first thirty days in the wild than it took for OpenAI to train the underlying model (GPT-3). Hence, when Jensen Huang — the CEO of NVIDIA — was asked about the impact of reasoning models on demand for his chips, his answer was… enthusiastic.

In sum: The algorithmic paradigms underpinning AI progress are still evolving extremely rapidly, and the way that they evolve from here will have enormous consequences on where, when, and how much computing power they demand.
Computing hardware efficiency
To date, the story of energy efficiency in the world of computing hardware has been nothing short of extraordinary. During the global boom in cloud computing and internet traffic through the last decade, demand for computing resources in data centers grew by nearly 10X, while data center energy use grew by just 10%.

This is a ridiculous rate of efficiency improvement. I can’t think of any other way in which humans use energy which has come even close. As I wrote early last year: “I wouldn’t believe it if the International Energy Agency didn’t say it was so.”
Here’s a bit more background:
“Over the past decade, the impact of tremendous growth in demand for computing was largely concealed from the electricity grid by equally tremendous improvements in the energy efficiency of data centers. Computing workloads were shifted from old, inefficient desktops & corporate server closets to hyper-efficient, hyper-scale data centers operated by some of the most sophisticated computing geniuses in the world.
But now, nearly all of those old, cord-clogged server closets are empty. We’ve already shifted most of the workloads that we’re going to shift into hyperscale data centers. And within those hyperscale data centers, additional investments in efficiency have begun to encounter wickedly diminishing returns. Google, Microsoft, et al have now plucked all of the low-hanging fruit, and then some.”
That said, even as we see diminishing marginal benefits from data center scale and operational sophistication, the semiconductor industry has stepped up to continue pushing the boundaries of energy efficiency at the chip and rack level. According to the fantastic researchers at EPOCH AI, the efficiency of leading-edge AI chips has been doubling every two years.

This progress is especially noteworthy because energy efficiency is not most chip designer’s primary objective. Their objective is to design the best chip possible for the next generation of AI models. This generally means taking advantage of Moore’s Law, which means increasing the density of transistors on a chip, in order to build bigger models with fewer data transmission bottlenecks.
Historically, Moore’s Law has also, naturally, led to higher efficiency, because narrower transistors consume less power. At this point, however, packing transistors more closely together is causing so much heat to build up on a chip that more intensive cooling is required to avoid frying the equipment. This effect is now overwhelming whatever efficiency advantage Moore’s Law delivers.
For now, this challenge can be overcome by switching to more energy efficient, but also more expensive liquid cooling systems. For example, here’s a close up on the evolution of NVIDIA’s top product lines. Holding all else equal, the rate of performance improvement over the last two generations of NVIDIA chips has slightly declined. The “Blackwell”, released in 2024, can only double the performance of the “Hopper” by upgrading to liquid cooling.

This trend has led to a very active ecosystem of companies developing higher efficiency cooling technology, and targeting a lower cost than established liquid cooling approaches. Good examples include “direct-to-chip” solutions like JetCool (which was acquired by the data center equipment provider Flex), or chip-level material science innovation, such as Akash Systems’ “chip-on-diamond” technology. (Did you know that, in addition to being one of the hardest materials on the planet, diamond is also one of the most thermally conductive?)
Yet, generally speaking, there’s only so much that cooling technology is going to be able to unlock additional data center efficiency. Mostly, I’ve come to see advanced cooling techniques as enablers of higher density racks, rather than independent levers for reducing power consumption.
In order to make a really big difference in data center power consumption, hardware innovation needs be able to match the order-of-magnitude level impacts associated with AI scaling laws. And as far as I know, there are only two major categories of hardware lever which could theoretically clear that bar: 1) Chip architecture, and 2) Photonics.
Chip architecture, to put it mildly, is not my area of expertise. But even for expert analysts, the frontiers of innovation in chip development are hard to observe, because so much of that innovation happens behind closed doors at the world’s most sophisticated tech companies. It’s striking that the only two players whose chips are called out in the EPOCH graphic above are NVIDIA and Google; and one of their few credible challengers is Amazon. There are also a few very well-funded startups, like Groq, whose flagship product is a chip designed specifically for 10X more efficient inference, as opposed to training.
If you’re smart enough to piece together what the chip designers at these companies are cooking up next… well, chances are you already have a generous offer on the table to go work for one of them.
Photonics, in this context, refers to the use of light as a data transfer medium. In my experience, lots of very smart people believe that it’s not just an area of innovation when it comes to the future of AI performance, but THE area of innovation. In short, that’s because the speed of computing operations which can be performed by an individual processing unit — a GPU or a CPU — has increased much faster than the bandwidth of the interconnections among those units as well as the chips responsible for memory.
AI relies on very large numbers of processors and memory chips being operated as a single, giant, interconnected supercomputer. Yet, since roughly the turn of the century, the number of “floating point operations” that an individual GPU can perform has increased by about 10,000 times, while the bandwidth of the connections between chips has only grown by about 100 times. For decades, AI researchers have been concerned that this disparity might someday lead to a “memory wall” which could curtail additional progress. Last year, a landmark paper argued that the industry is rapidly approaching that theoretical limit:
“Despite many innovations in memory technology, this trend shows that the ‘memory wall’ is increasingly becoming the dominant bottleneck for a range of AI tasks.”
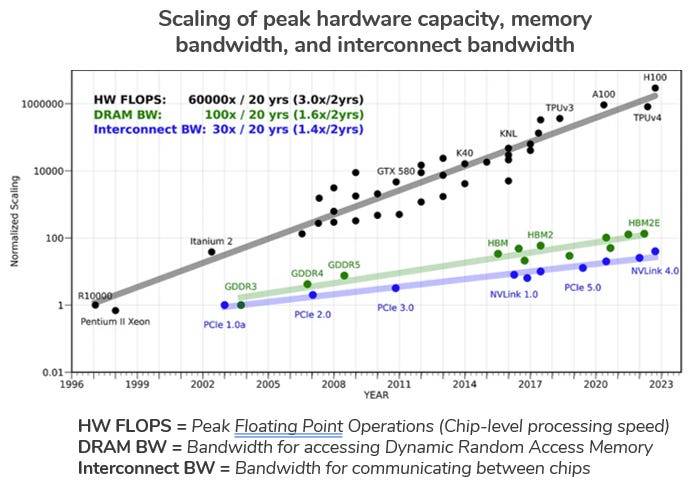
AI developers care about the memory wall mostly because it limits the speed of AI processing. Ultimately, this bottleneck puts a hard theoretical cap on our ability to continue increasing the scale of AI models. In the meantime, it has all kinds of negative impacts on the economics of the endeavor.
One of those negative impacts is wasted energy, because while processors are waiting for data to be transferred from one unit to another… they’re still running, which means they’re still consuming energy. For a system transferring data between processors and memory units kajillions of times per second, even miniscule delays can really add up. So, the more the gap between processing speed and memory bandwidth widens, the more energy will be wasted.
That brings me back to photonics. The promise of “photonic” or “optical” interconnections is that they can break through the memory wall, because signals delivered by light over a fiberoptic cable are able to transmit much more data than signals delivered by electricity over a copper wire. Photonic interconnections are already being employed, in some cases, between clusters of racks in a data center. However, there are now a number of companies developing solutions for shrinking photonics down to the level of individual chips. See, for example, Xscape Photonics and Ayer Labs.
How much energy could this save? It’s very hard to say, because photonic interconnections are largely viewed by AI researchers as a means of overcoming the memory wall, not as an independent efficiency measure. Hence, practically speaking, the technology might only be adopted in order to pursue an otherwise unattainable level of AI scale — which could lead to a world with even more AI-driven energy consumption! (This would be a pretty stark example of the famous Jevons Paradox.)
That brings me to the final big source of uncertainty clouding the future of AI.
Power supply constraints
One of the reasons nobody knows how much energy AI will consume is that there are limits on how much energy will be available for AI to consume. In fact, access to power is shaping up to be the strictest constraint on data center development, in most regions, through at least the end of the decade.
The US power grid currently has about 950 gigawatts of dispatchable capacity.1 According to the North American Electric Reliability Corporation2, the vast majority of this capacity is already spoken for. In fact, the majority of the US and Canada are now facing an elevated risk of power supply shortfalls in the next four years.
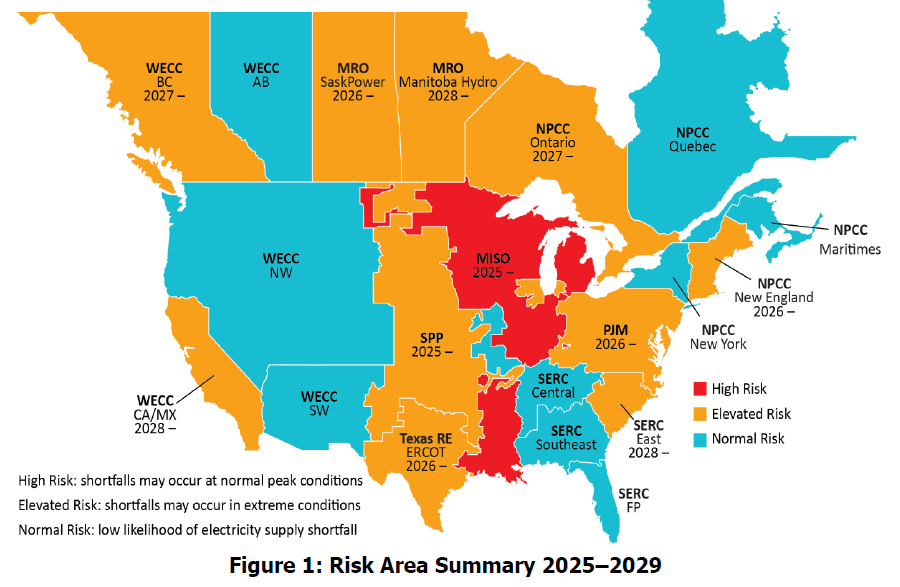
So: How much more capacity can be built, and how quickly, in order to serve AI computing demand?
Let’s consider our options:
I. Natural gas power:
In the US, gas is the go-to option for firm, reliable capacity additions. Deployment has been very consistent for the past two decades — averaging around 8 gigawatts of additions per year. (This followed a boom in 2000-2005 which peaked at 50 gigwatts deployed in 2002, and left the industry wary of over-investment.) Now, the “big three” global gas turbine vendors are reportedly sold out through at least 2030. While these companies certainly see the opportunity to invest in manufacturing capacity expansion, they’re also being careful not to repeat the mistakes of the early 2000s.
The Energy Information Administration (EIA) now projects the pace of natural gas additions nearly doubling to an average of 15 gigawatts per year from 2026 through 2030. Beyond that, the industry could theoretically pick up the pace of additions even more. However, moving into the 2030s, I believe that gas turbine deployment will most likely remain constrained by a combination of several factors:
Bottlenecks in natural gas production & pipeline infrastructure investment — especially given that the US is also on track to double liquefied natural gas exports by 2030. There is clearly a risk of imbalances in supply and demand which cause prices to spike, much like they did several times between 2000 and 2010.
Limits on manufacturing capacity — such as the turbine supply constraints which the industry is already experiencing.
Climate policy at the state level, and depending on the next set of elections, perhaps also at the federal level.
II. Renewables and battery storage:
Batteries are the rising star in the dispatchable capacity market. Deployment surged last year, with nearly 13 gigawatts installed in the US. Theoretically, this number could continue to grow rapidly, as there is plenty of lithium-ion battery supply available worldwide, and storage systems are not particularly complex or time-consuming to install.
Yet, battery storage is not quite “dispatchable” in the same way as a gas turbine, because batteries are “duration limited”. (A 1 MW battery containing 4 MWh of energy can only be dispatched at its full “nameplate” capacity for 4 hours straight.) As more batteries are installed, we’ll need to add more hours of storage to each tranche of additions, which means that the cost of battery storage will probably increase as a function of its deployment. This will be the case even as grid storage technology continues to improve, although technology like Form Energy’s multi-day batteries could make a big difference.
For now, in some places, the combination of renewables and batteries can be deployed relatively quickly and cost-effectively. However, these locations have become harder to come by in recent years, because of electric transmission constraints and other restrictions on solar & wind project development. (For more information on these problems, I’d suggest my prior posts: “Where have all the transmission lines gone?” and “Locals Against Renewables”.) On the other hand, I believe there may be an opportunity for some large data centers to avoid these bottlenecks by going fully off-grid. (Check out: “Is the future of low-carbon industry off-grid?”)

The cost of solar & wind energy has also increased over the past five years for a number of other reasons, which I outlined in “Adolescence for renewables, Retirement for oil”. And renewables are probably going to become even more expensive following cuts to longstanding tax credits contained in the current version of the Republican party’s “Big Beautiful Bill”. Moreover, tariffs and related geopolitical uncertainty are a major risk factor, given America’s continued reliance on China’s solar and battery supply chains. (See: “A tale of two energy superpowers”.)
To sum up: I still see great potential in the combination of renewables and storage to rapidly serve new data center load. However, this potential comes with especially big error bars, due to a number of major risk factors. In an optimistic scenario, they could probably rival the scale of new gas generation — but I’d estimate that their total contribution will be closer to 50 GW of additional, dispatchable capacity by 2030.
III. Nuclear and geothermal:
With every passing month, I’ve become more bullish on the prospects for a nuclear renaissance. As I wrote back in December of last year: “It’s time to build! (light water reactors)”. In my view, the most exciting energy story of the year so far was Elementl Power, an EIP portfolio company, signing a strategic agreement with Google to begin developing three nuclear projects totaling about 1.8 gigawatts.
Perhaps the next most exciting story was Fervo Energy’s announcement that it had successfully drilled a geothermal well three miles deep, to a temperature of 270 degrees Celsius, in just 16 days. Fervo has been an incredible champion for geothermal, and I suspect that the technical progress they’ve made will create major ripple effects throughout the industry.
In the case of both nuclear and geothermal, the timeline to bring multiple gigawatts of new capacity online is probably around ten years. However, if we continue to invest in their long-term growth, I believe that they could each become substantial incremental contributors to our energy supply beginning in the mid-2030s. In the US, we could easily add more than 10 GW of nuclear capacity per year (as we did during the 1970s). Geothermal will probably amount to less, given that even “enhanced” geothermal is probably going to be limited to sites in the Western US, where heat naturally rises closer to the earth’s surface.
IV. What about “the grid” and distributed energy?
All of the aforementioned capacity resources will continue to rely, for the most part, on the bulk electric power grid — which has tremendous efficiency and reliability benefits compared with small, isolated systems. However, at this point, the supply chain for many of the key components of “the grid” is also a risk factor in the race to serve new data center load. “The price of power grids” is already increasing, while the typical lead time for critical equipment, like large power transformers and switchgear, now exceeds 3 years.
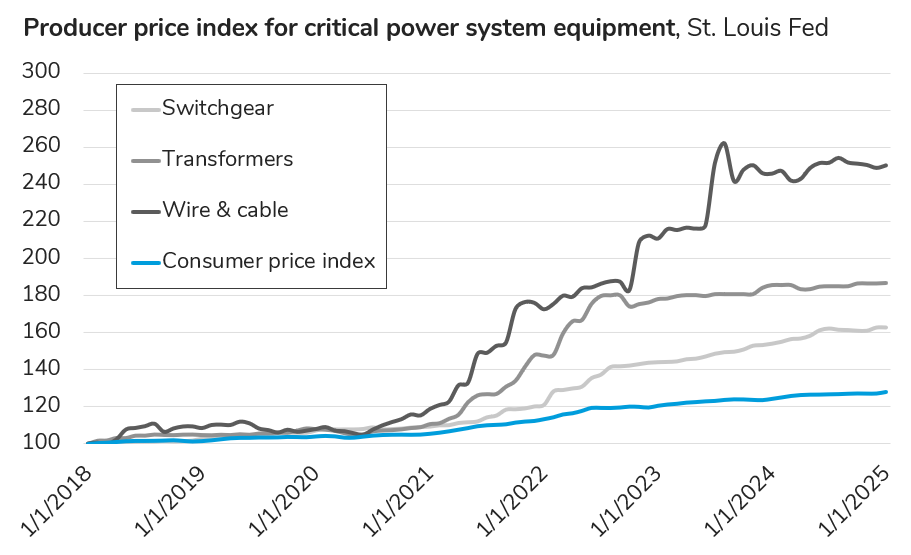
One option for freeing up grid capacity is doubling down on energy efficiency and load flexibility. By definition, these “distributed energy resources” are situated at the edge of the grid, downstream of essentially all of the potential bottlenecks we see in transmission and distribution. In part because of the pressure that rapid demand growth is putting on the grid, and in part because distributed energy technology is becoming more sophisticated, utilities are already beginning to take these kinds of resources more seriously. In the words of one North American utility CEO (in a closed door session, so I’ve kept this anonymous)…
“This is the first time we've really thought about [DERs] as a planning resource. It used to be about saving energy for savings’ sake. Now, it’s about saving for growth.”
In order to get a sense of what a more sophisticated approach to load flexibility looks like, I’d recommend checking out GridBeyond, one of our portfolio companies at EIP.
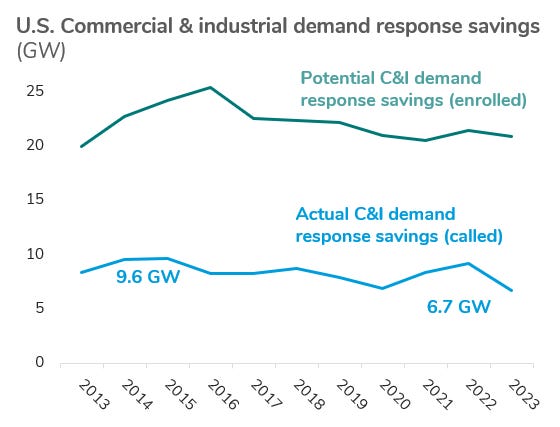
The team at GridBeyond are specialists in the field of industrial load management. Many industrial sites have some historical experience with “demand response” programs, which have typically involved a grid operator picking up a telephone and calling a facility manger, to ask if he or she could turn down some piece of machinery for a few hours. GridBeyond has developed a much more automated approach which accounts for the specific process-flow diagrams and operational nuances in a wide range of facilities. (Think of cement plants, or paper mills.) The company is also a leader in deploying and dispatching battery storage systems on these kinds of sites.
Today, across the entire US, there is only about 20 GW of load actively enrolled in legacy demand response programs. That’s actually down from a peak of 25 GW back in 2016. I believe that we could at least triple this amount with new approaches like those GridBeyond has pioneered.
I’m also increasingly bullish on the prospect for “microgrids”, which I define as segments of the “macro” grid which can run independently during power outages, but still interoperable with the rest of the system during the 99.97% of the time when things are running smoothly. As I wrote in a prior post:
“Microgrids are not just a way to accelerate time to power. They can also be the most affordable source of new capacity for the system as a whole. For example, our portfolio company Enchanted Rock has been a pioneer in deploying microgrids which are capable of supplying power to the grid for hundreds of hours a year (or more), while also offering their host customers an additional layer of resilience against sustained outages. We’re seeing an increasing number of electric utilites develop programs to deploy this kind of distributed generation as a means of serving new demand in a timely and cost-effective manner.”
So, how much capacity will be available for AI?
This brings me back to the question at hand: How much new dispatchable capacity can we build to serve growing AI data center demand?
Here’s my (extremely) rough math. In a reasonably optimistic, but not outlandish scenario, I can see America adding…
… In the next ten years: ~200 GW of natural gas generation (some of it distributed) + ~150 GW of firm capacity from renewables, storage, and load flexibility
… In the following ten years (2035-45): Another 100 GW of natural gas generation (with additions slowing down due to carbon policy constraints, and perhaps the added cost of carbon capture) + 300 GW of renewables and storage (assuming a major uptick in transmission investment) + ~150 GW of nuclear + ~50 GW of geothermal
That suggests a grand total of around 950 gigawatts of new dispatchable capacity in the next twenty years — practically doubling the size of the existing power system. But of course, not all of that capacity will be available to data centers. Some will need to replace our country’s aging fleet of coal-fired power plants, which will almost certainly all be retired within this timeframe; and some will need to serve all of the other sources of electricity demand growth, such as electric vehicles and heat pumps, not to mention baseline economic expansion.
So, my best guess is that there is a hard cap of several hundred gigawatts available to power AI within the next twenty years…
… Which leaves me in the same place as all of the best forecasters in the business: I have no idea whether that’s enough.
Enjoy this post? Try another one on the intersection of AI, energy, and climate…

By “dispatchable”, I’m referring to resources which can be counted on to provide power, with a high degree of certainty, when called on to do so.
A non-profit entity tasked with ensuring power grid reliability across the continent.
Really enjoyed this, Andy. I hadn't fully appreciated the shift from training-focused to inference-focused scaling laws change the infrastructure requirements.
A bunch of unstructured questions that came to mind while reading:
1. Could photonics actually accelerate AI power consumption (i.e., Jevens Paradox)?
2. How feasible are distributed, lower-capacity installations near population centers given grid constraints and real estate costs?
3. If data residency and latency issues continue to abound, does compute become a 'grid tied' asset like electrons? And could AI infra players participate in grid services by selling marginal energy? And, come to think of it, could you have a similar model for marginal local compute?
4. If multi-GW AI clusters start competing for the same finite grid access points, could we see a bifurcation where only vertically integrated players (who can control land, power development, and compute) can actually execute at scale? + then does that create a new category of infrastructure asset - some kind of "shovel-ready AI site"
5. To what extent will energy demand from hyperscalers lead them to pay higher energy prices that anchor technologies which otherwise wouldn't deploy commercially, at scale, soon)? (e.g., LDES, SMRs, hydrogen turbines)
This analysis highlights why we need diverse forecasting approaches. We should be developing projections based on two parallel scenarios:
Scenario 1: Unconstrained AI Demand - Bottom-up modeling based on factors like wafer fabrication, GPU sales volume, token demand, and development-related compute budgets. This shows us where the AI industry wants to go without ceilings.
Scenario 2: Grid-Constrained Reality - Top-down analysis of actual generation capacity additions, interconnection queue timelines, transmission bottlenecks, and regional supply shortfalls. This shows us what's actually possible.
The gap between these scenarios would be incredibly revealing - not just for energy planning, but for understanding which AI development paths are viable versus which are fantasies. Solutions that push the second scenario closer to the first are essential for American leadership in this space.